

NEAR, O protocolo fácil de usar, neutro em carbono, construído desde o início para ter desempenho, segurança e escalabilidade incomparável. Em termos técnicos, NEAR é uma blockchain camada um, fragmentada, proof-of-stake construída com a usabilidade em mente. Em termos simples, NEAR é um blockchain para todos.
Hoje, temos o prazer de anunciar o conjunto de dados públicos NEAR BigQuery para quem deseja consultar dados de blockchain de maneira fácil e econômica.
Por que o conjunto de dados público do BigQuery
Até agora, as necessidades de consulta de dados de um usuário eram atendidas por indexadores. Esses indexadores foram fornecidos pela NEAR Protocol ou feitos sob medida. Para construir indexadores personalizados, era necessário que os arquivos JSON da camada de armazenamento NEAR Lake fossem transformados e carregados em um mecanismo de banco de dados de destino como o PostgreSQL, e só então um usuário poderia executar consultas nele. Essa abordagem é complexa, demorada e consome muitos recursos. Requer monitoramento constante para garantir que os bancos de dados tenham as informações mais atualizadas.
O conjunto de dados público NEAR BigQuery muda isso. Ele fornece dados de blockchain quase em tempo real que podem ser facilmente consultados com SQL.
O que fizemos
Construímos a NEAR LakeHouse no Databricks. Os dados são carregados em arquivos bronze brutos usando o Databricks Autoloader, e transformado com Tabelas dinâmicas Delta do Databricks em mesas de prata limpas e enriquecidas seguindo Arquitetura Medallion do Databricks. As tabelas prateadas são então copiadas para o Conjunto de dados públicos do GCP BigQuery pronto para consumo.
O desenho da solução
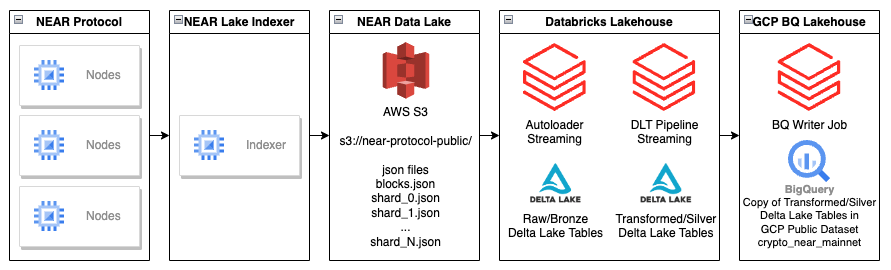
O código é open-source e pode ser encontrado em nosso repositório GitHub: near/near-public-lakehouse.
Para saber mais sobre como começar e os dados disponíveis, consulte nossa documentação:
https://docs.near.org/bos/queryapi/big-query
Benefícios
- Insights quase instantâneos: dados históricos on-chain consultados em escala.
- Econômico: elimina a necessidade de armazenar e processar dados em massa do protocolo NEAR; consulte o mínimo ou o máximo de dados que preferir.
- Fácil de usar: não é necessária experiência prévia com tecnologia blockchain; traz um conhecimento geral de SQL para desbloquear insights.
Conclusão
O NEAR BigQuery Public Dataset agora está disponível para qualquer pessoa que queira aproveitar dados de blockchain para suas próprias necessidades. O BigQuery pode ajudar não apenas os desenvolvedores, mas também públicos mais amplos, incluindo:
- Usuários: crie consultas para rastrear ativos do protocolo NEAR, monitorar transações ou analisar eventos na cadeia em grande escala.
- Pesquisadores: use dados indexados para tarefas de ciência de dados, incluindo atividades em cadeia, identificação de tendências ou alimentação de pipelines de IA/ML para análise preditiva.
- Startups: Use os dados indexados do protocolo NEAR para obter insights profundos sobre o envolvimento do usuário, utilização de contratos inteligentes ou insights sobre tokens e adoção de NFT.
Fonte: near.org







